Demystifying Data Mesh: A Game-Changer for Future-proof Data Architecture
We need to shift to a paradigm that draws from modern distributed architecture: considering domains as the first class concern, applying platform thinking to create self-serve data infrastructure, and treating data as a product.
Zhamak Deghani
The concept of data mesh was first coined by Zhamak Deghani in 2019, when she was a director of emerging technologies at Thoughtworks. In an in-depth write-up she presented a problem underlying current data architecture: infrastructure was centralised and monolithic, alienating data producers from consumers.
But as data was becoming more abundant, and our use cases for it more complex and variable. Previously data was mainly used for business intelligence; now we were using it to design products, optimise workflows and empower employees – existing architecture lacked the flexibility optimally serve all those consumers.
Her solution is a paradigm shift, which involves decentralising your data architecture and reframing data ownership and processing. A decentralised system allows for local data ownership and governance, improving data quality and security. Almost more importantly, presenting data as a product and creating self-service platforms allows wider access and consumption of the data, means it becomes easier to embed it in all levels of an organisation.
The Core Principles
Domain Ownership:
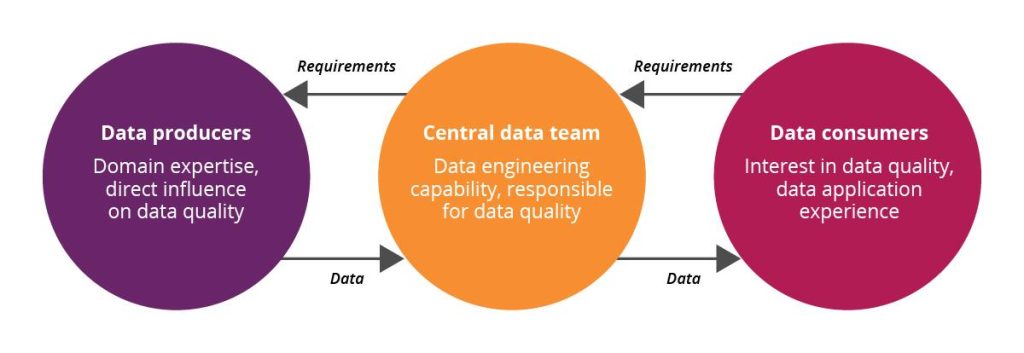
Traditionally data has been centralised in data warehouses or data lakes, with one team being responsible for its quality and distribution, as well as the maintenance of the infrastructure. This can create bottlenecks in distribution and places pressure on the data team. While they are responsible for data quality and delivery, they might lack the specific expertise about its collection and application – creating a disconnect.
One of the core ideas within a data mesh is decentralisation in the form of domain ownership. This cuts out the middleman and means that the people responsible for data production, are also the ones who ensure its quality and prepare it for application. In short, each domain that produces data will also be tasked with transforming it into a product ready for consumption.
Traditional approaches to data can create a disconnect between data owners and users. Source
Data as a Product:
The second principle of data mesh is to reframe data as a product. Essentially, the domain team which produces the data needs apply product thinking and prepare the data in ways which are most valuable to its consumers.
The data product goes beyond the mere data set; it encompasses code for data pipelines, metadata, and infrastructure too. To have any value the data product must also fulfil certain conditions: it must be discoverable, addressable, self-describing, secure, trustworthy, and interoperable.
Self-Serve Data Platforms:
Another pillar of data mesh is the idea of a self-serve data infrastructure. This infrastructure should be domain agnostic and hide the complexities of data provisioning from its users, which would allow even users with less specialised knowledge to access and use the data.
Deghani envisioned that within such platforms, there could be multiple planes which provide access to specialised capabilities, catering to different consumer’s needs. Essentially, through abstraction the infrastructure removes barriers to accessing the data and creates autonomy for users.
Federated Governance:
This last principle safeguards interoperability within the data mesh. One of the benefits of the data mesh is that it confers autonomy and responsibility to the domains and consumers within the mesh. However, if the domains, products, and interfaces are not governed by a standardised set of rules, they will soon cease to be interoperable. The governance challenge is to balance local autonomy with global conventions and standards.
A New Philosophy
This write-up is surface-level, but for anyone looking to dive deeper into the concept, there are many excellent articles available online – including articles by Deghani herself, exploring the principles and architecture.
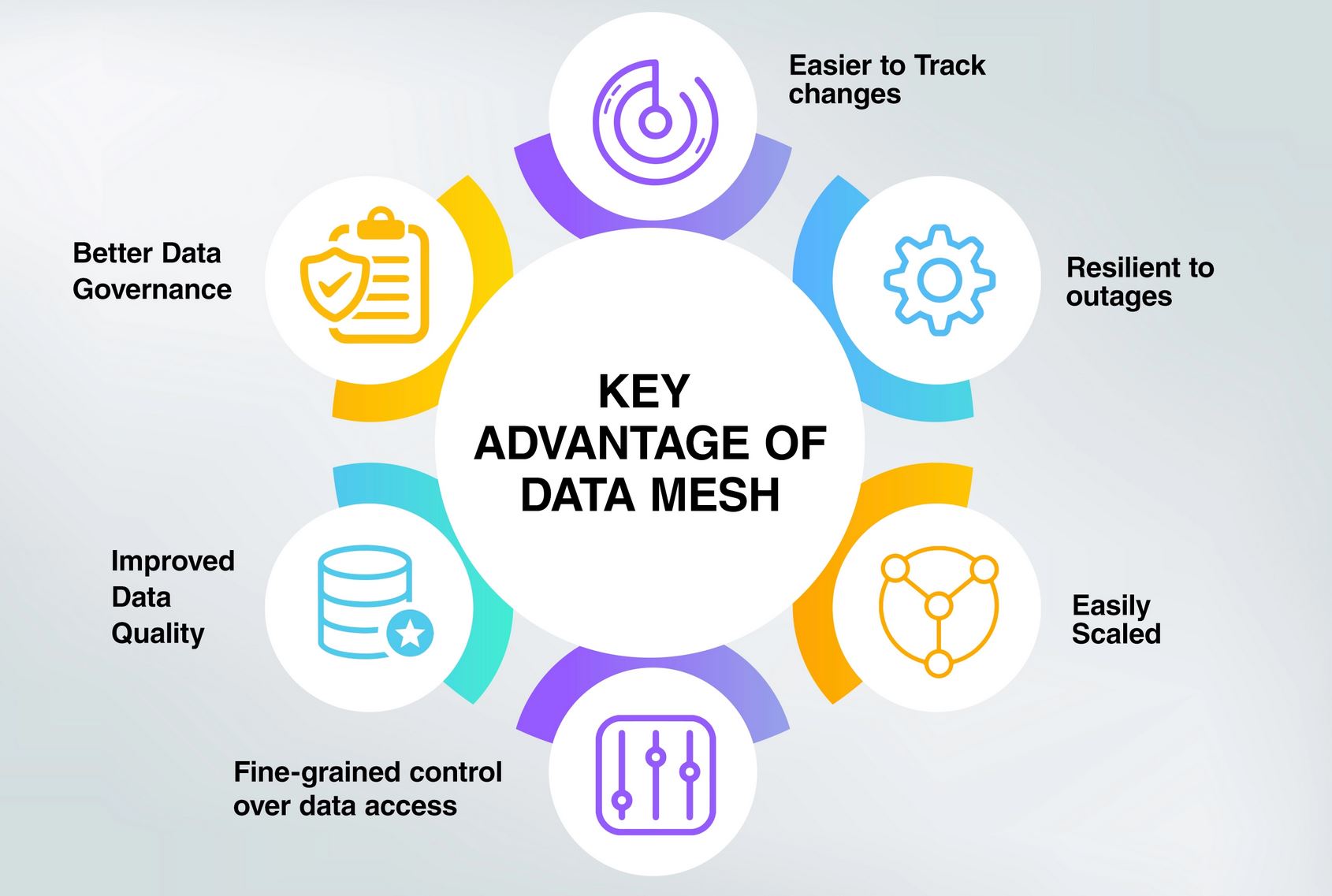
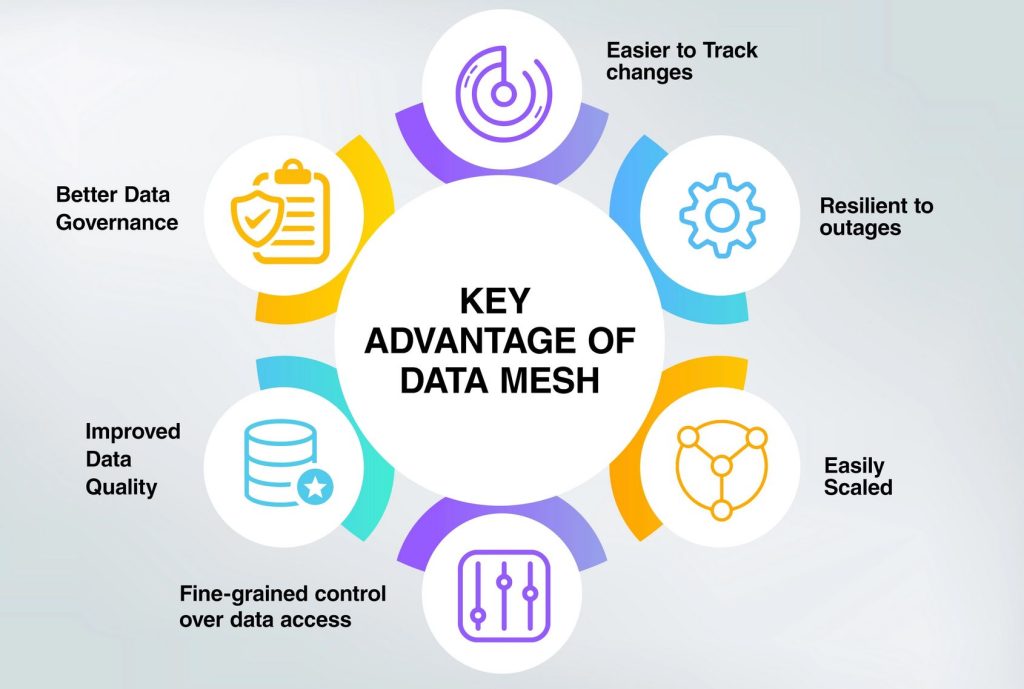
Potential key advantages of having a data mesh over more traditional architecture. Source
There are compelling reasons to adopting a data mesh over a more traditionally centralised architecture. For starters, it promises improved data quality and scalability, as well as higher resilience to outages. It would also make it easier for anyone within an organisation to access and harness the data, regardless of their data engineering skills. There is also no need for central maintenance and hierarchy, as each domain is responsible for maintenance and control of its own node.
The most important takeaway from this, or any other article about data mesh, is that its not a singular technology. It’s almost a design philosophy which affects how you build your infrastructure and implement technology.